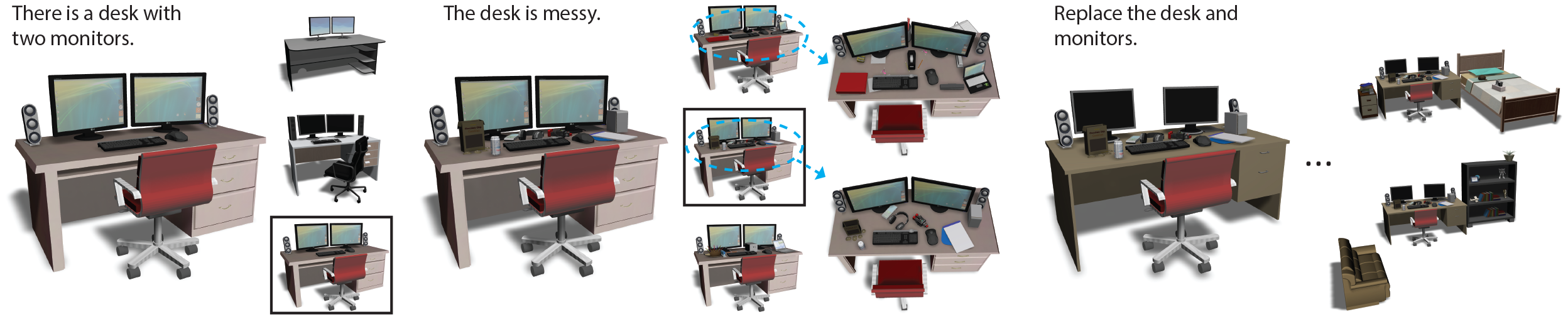
We introduce a novel framework for using natural language to generate and edit 3D indoor scenes, harnessing scene semantics and text-scene grounding knowledge learned from large annotated 3D scene databases. The advantage of natural language editing interfaces is strongest when performing semantic operations at the sub-scene level, acting on groups of objects. We learn how to manipulate these sub-scenes by analyzing existing 3D scenes.We perform edits by first parsing a natural language command from the user and transforming it into a semantic scene graph that is used to retrieve corresponding sub-scenes from the databases that match the command. We then augment this retrieved sub-scene by incorporating other objects that may be implied by the scene context. Finally, a new 3D scene is synthesized by aligning the augmented sub-scene with the user's current scene, where new objects are spliced into the environment, possibly triggering appropriate adjustments to the existing scene arrangement. A suggestive modeling interface with multiple interpretations of user commands is used to alleviate ambiguities in natural language. We conduct studies comparing our approach against both prior text-to-scene work and artist-made scenes and find that our method significantly outperforms prior work and is comparable to handmade scenes even when complex and varied natural sentences are used.
If you find this work useful for your research, please cite our paper using the Bibtex below:
@inproceedings{ma2018language, title={Language-driven synthesis of 3D scenes from scene databases}, author={Ma, Rui and Patil, Akshay Gadi and Fisher, Matthew and Li, Manyi and Pirk, Sören and Hua, Binh-Son and Yeung, Sai-Kit and Tong, Xin and Guibas, Leonidas and Zhang, Hao}, booktitle={SIGGRAPH Asia 2018 Technical Papers}, pages={212}, year={2018}, organization={ACM}}
We thank the anonymous reviewers for their valuable comments.This work was supported, in parts, by an NSERC grant (611370), an NSF grant IIS-1528025, the Stanford AI Lab-Toyota Center for Artificial Intelligence Research, the Singapore MOE Academic Research Fund MOE2016-T2-2-154, an internal grant from HKUST (R9429), and gift funds from Adobe and Amazon AWS. We also thank Phuchong Yamchomsuan for creating the artist scenes, as well as Quang-Hieu Pham and Chenyang Zhu for helping with pre-processing the scene databases.
* Co-First Authors